
Ant Group's Platform Engineering Practice at Scale
· One min read
It has been more than eight years since the first commit of Kubernetes, and the cloud-native technology represented by it is no longer new but a "default option" for modern applications. The services that modern applications rely on are far more than just Kubernetes. A slightly more complex application often uses heterogeneous infrastructures such as Kubernetes ecological cloud-native technology, IaaS cloud services, and internal self-built systems. Multi-clouds and hybrid clouds are also usually required. We have entered the "Post cloud-native Era", and the operation tools only for Kubernetes can no longer meet our demands.
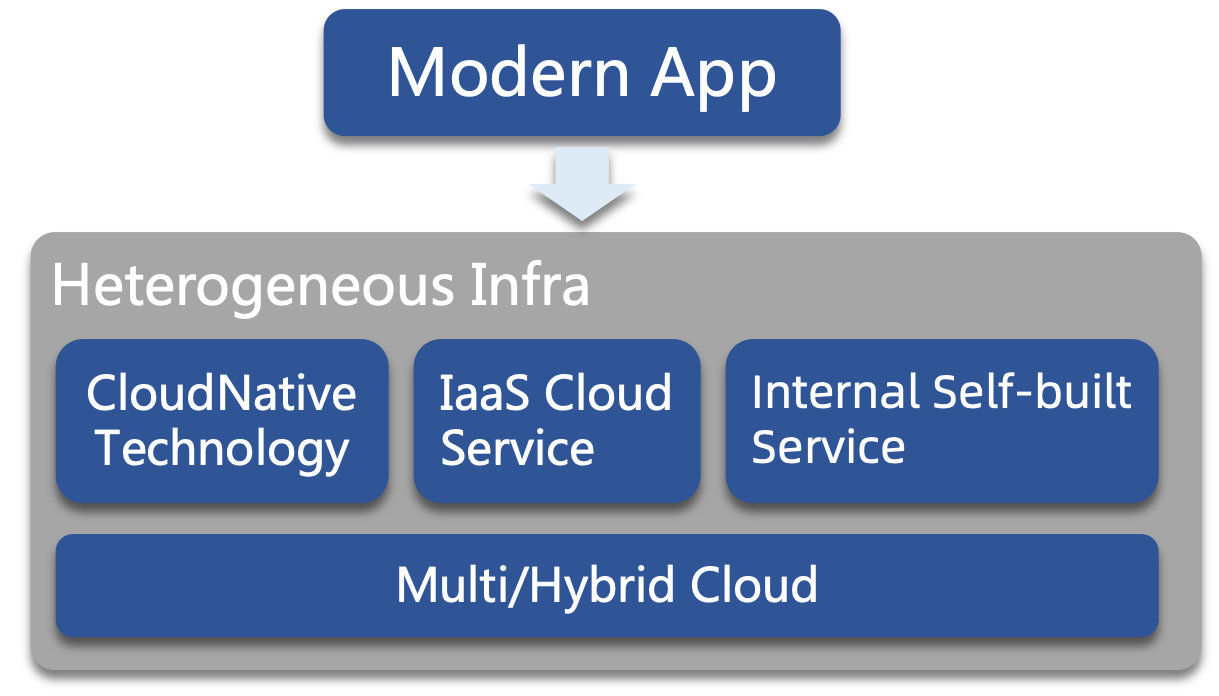
What's more complicated is that, within the enterprise, different teams generally maintain these services. A large-scale operation requires the cooperation of members of multiple teams. However, there is a lack of efficient communication and collaborative approach among App Dev, Platform Dev, and SRE teams. The complexity of technology and inefficient teamwork has exponentially increased the difficulty of large-scale operation and maintenance in the "Post cloud-native Era".
The large-scale operation of complex heterogeneous infrastructure is not a unique problem in the post cloud-native era. It has always been a problem since the birth of distributed systems, but it has become more difficult in the post cloud-native era. The industry proposed the DevOps concept more than ten years ago. Countless companies have built their DevOps platforms based on this concept, hoping to solve this problem, but the actual implementation process is often unsatisfactory. How to cooperate between the Dev team and the Ops team? How are responsibilities divided? How can a platform team of dozens of people support the operation demands of tens of thousands of engineers? The underlying infrastructure is complex and diverse, and capabilities change with each passing day. How to quickly help front-line Devs get technological advantages? These problems still need to be resolved. Recently, some people have suggested that DevOps is dead and Platform Engineering is the future. Regardless of the concept definition, whether DevOps or Platform Engineering, they are essentially different concepts under the same proposition of large-scale operation in enterprises. What we need more is a solution that conforms to the trend of technological development and can solve current problems.
In traditional operation and maintenance thinking, the solution to the above problems is generally to build a PaaS platform, such as our early AntGroup PaaS platform, a web console with a UI interface. Users (usually App Dev or SRE) can accomplish operations such as deploying, restarting, scaling, and so on through UI interactions. In terms of technical implementation, the system mainly contains three parts, a frontend system that provides user interactions regarded as the system entrance; a backend system in the middle that connects to various infrastructures; the bottom layer is the APIs of multiple infrastructures. This architecture has been running for nearly ten years and has been running very well. It has a user-friendly interface and can shield the complexity of the infrastructure, and the responsibilities of each team are clearly defined. However, in the post cloud-native era, this architecture is no longer applicable, exposing two fatal flaws, "manpower-consuming" and "time-consuming".
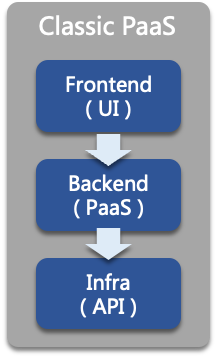
To give a typical example, the network team has developed a new load balance algorithm for its Loadbalancer, which needs to be provided to users. Under the above architecture, the entire workflow looks like this:
There is a problem here. Even a tiny feature requires the PaaS backend and frontend to modify the code. The process will take a week to go online at the fastest, and the more infrastructure teams involved, the lower the efficiency. It was not a problem ten years ago but is a big problem today. A post cloud-native era modern application relying on three cloud-native technologies (Kubernetes + Istio + Prometheus), two cloud services ( Loadbalancer + Database), and a self-built internal service has already become prevalent, and complex applications will rely on more. If every infrastructure is hard-coded by the PaaS team, expanding the PaaS team by ten times will not be enough.
After talking about "manpower-consuming", let's look at the problem of "time-consuming". A minor feature in the above example requires two cross-team collaborations. The first collaboration is between the infrastructure team and the PaaS backend team, and the second is between the PaaS backend team and the PaaS frontend team. Teamwork is a complicated problem, sometimes more complicated than the technology itself. If you want to accomplish a large-scale operation with 100 applications at a time, how many teams do you need to communicate and collaborate with? How much time will it take? Without suitable coordination mechanisms, this becomes an impossible task.
We have been exploring within Ant Group for nearly two years. We have practiced common tools such as kustomize, helm, argoCD, and Terraform and even developed some auxiliary systems for some tools, but the results are unsatisfactory. Some of these tools are too limited to the Kubernetes ecosystem to operate other types of infrastructure. The others support heterogeneous infrastructure but are not friendly to the Kubernetes ecosystem and cannot take advantage of cloud-native technologies. More importantly, upgrading operation tools has hardly improved teamwork efficiency, and we need a more systematic solution. Going back to the question itself, we propose two ideas for the problems of "manpower-consuming" and "time-consuming":
From a technical point of view, the PaaS platform must provide flexible toolchains and workflows. All capabilities of the infrastructure are exposed in a modular manner. App Dev combines and orchestrates these platforms' basic capabilities to solve their problems, and the process does not require the participation of the platform team. All teams involved in the whole process use a unified language and interface to communicate without manual involvement in the entire process.
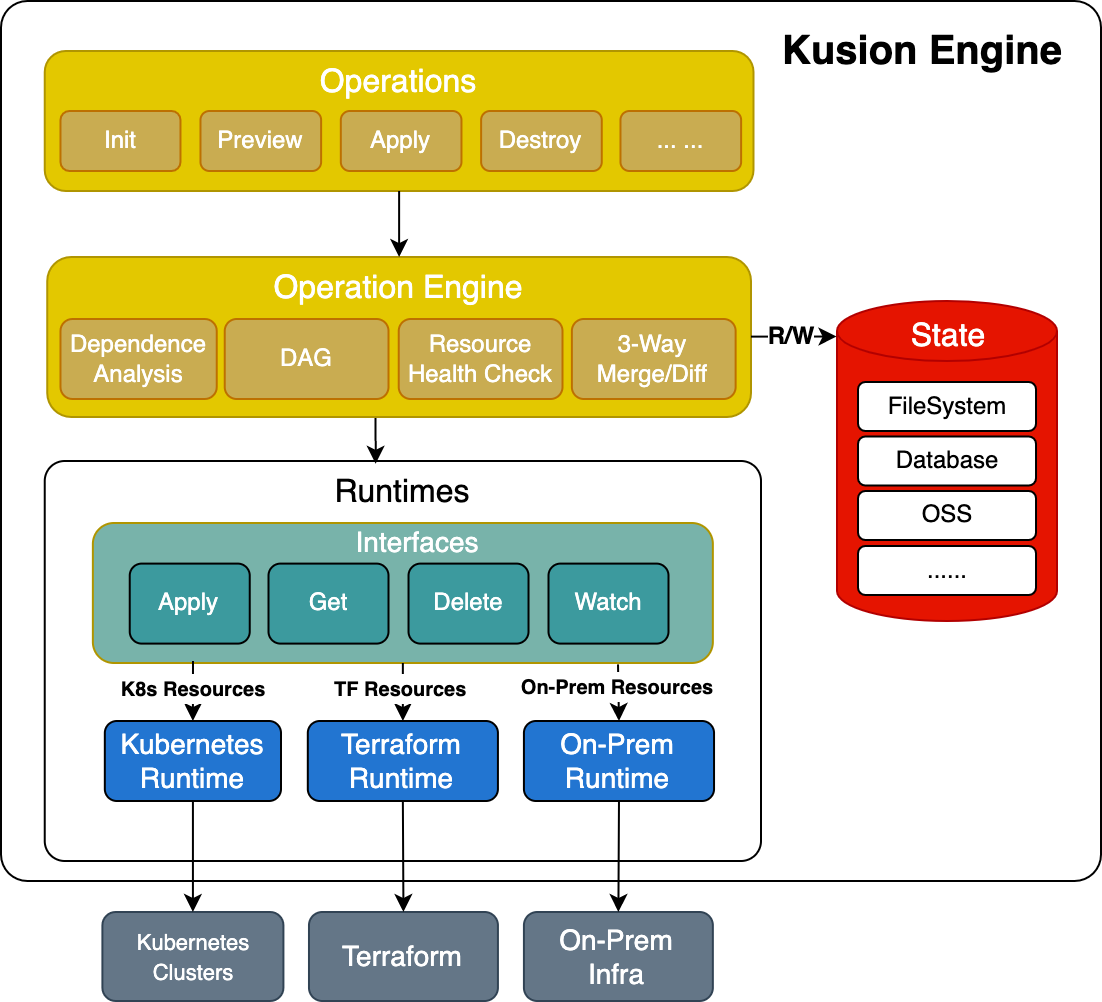
After nearly two years of exploration and practice on the AntGroup's internal PaaS platform, we precipitated a complete end-to-end solution named KusionStack, which is open source now. KusionStack is designed to solve the traditional PaaS "manpower-consuming consuming" and "time-consuming" problems from the perspective of unified heterogeneous infrastructure operation and team collaboration. The whole system mainly contains three parts:
Platform Dev defines the basic capability model through KCL, and App Dev reuses these predefined capabilities in the application configuration model (AppConfig) through language features such as import and mixin. Users can quickly describe operation intentions in Konfig. AppConfig is a well-designed model that only exposes the attributes that App Dev needs to care about, shielding the complexity of the infrastructure.
Never underestimate the professionalism and complexity of infrastructures. Even Kubernetes, which has become the standard of cloud-native technology, still has a high threshold for ordinary users. A Kubernetes Deployment has dozens of fields, let alone custom labels and annotations. Ordinary users cannot understand them all. In other words, AppDev should not understand Kubernetes, all they need is release, and they do not even need to care whether the underlying infrastructure is Kubernetes.
AppConfig will generate multiple heterogeneous infrastructure resources after compilation and transfer these resources to the KusionStack engine through CI, CLI, GUI, etc. The engine is the core of KusionStack, responsible for all operations, and makes the operation intentions take effect on the infrastructure. It operates heterogeneous infrastructure in a unified way and performs a series of procedures on these resources, such as verification, arrangement, preview, validation, observation, and health check.
It is worth mentioning that the whole process is very friendly to Kubernetes resources. Due to the Kubernetes reconciliation mechanism, the success of the apply command does not mean that resources are available. Applications need to wait for resources to be reconciled successfully. If the reconciliation fails, we need to log in to the cluster and check the specific error message through commands like get, describe, and log. The whole process is very cumbersome. We have simplified these operations through technical means and showed important messages during the reconciliation in a user-friendly way. The animation below is a simple example. After the command is invoked, you can clearly see the reconciliation process of all resources and their associated resources until the resources are actually available.
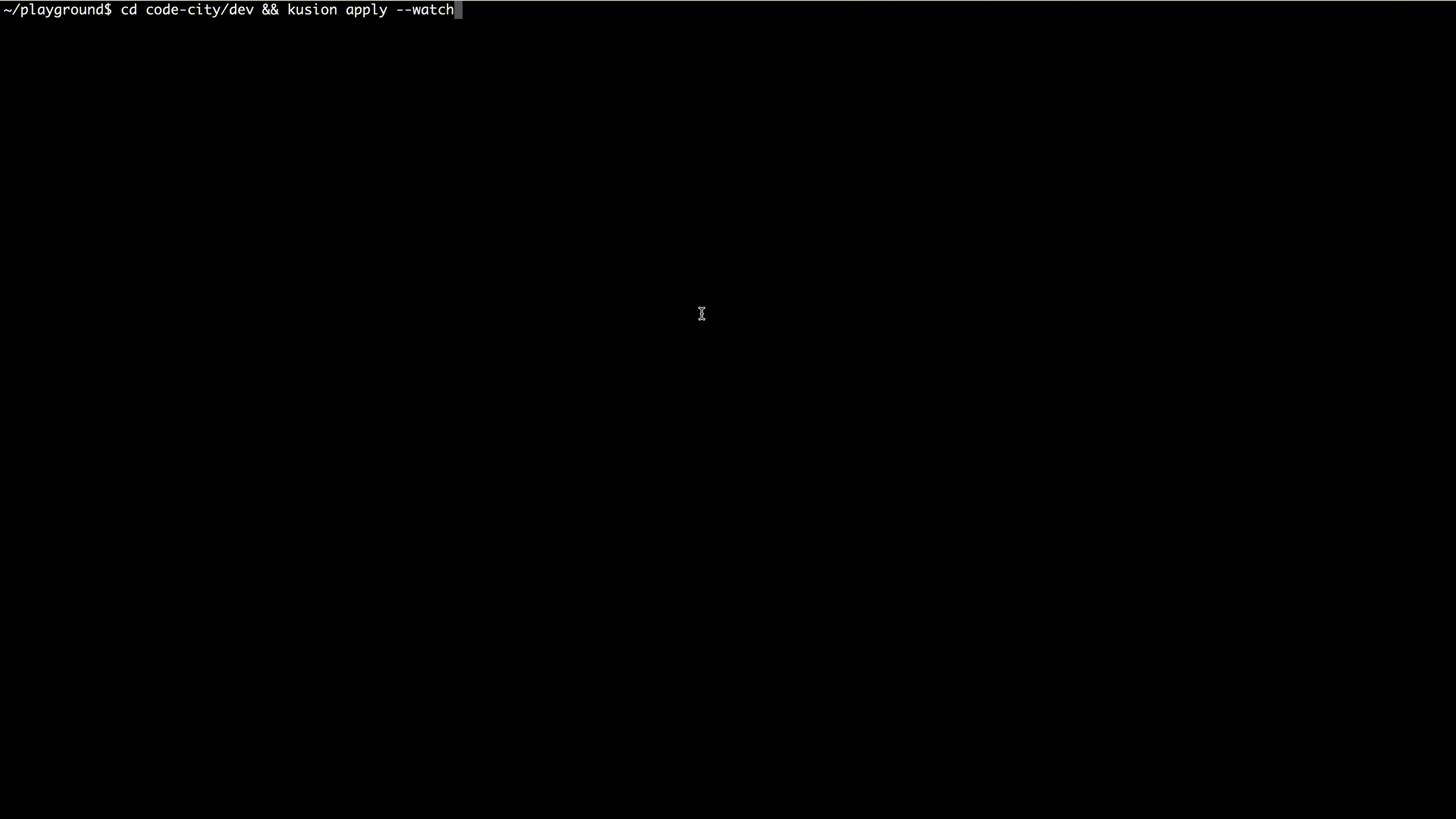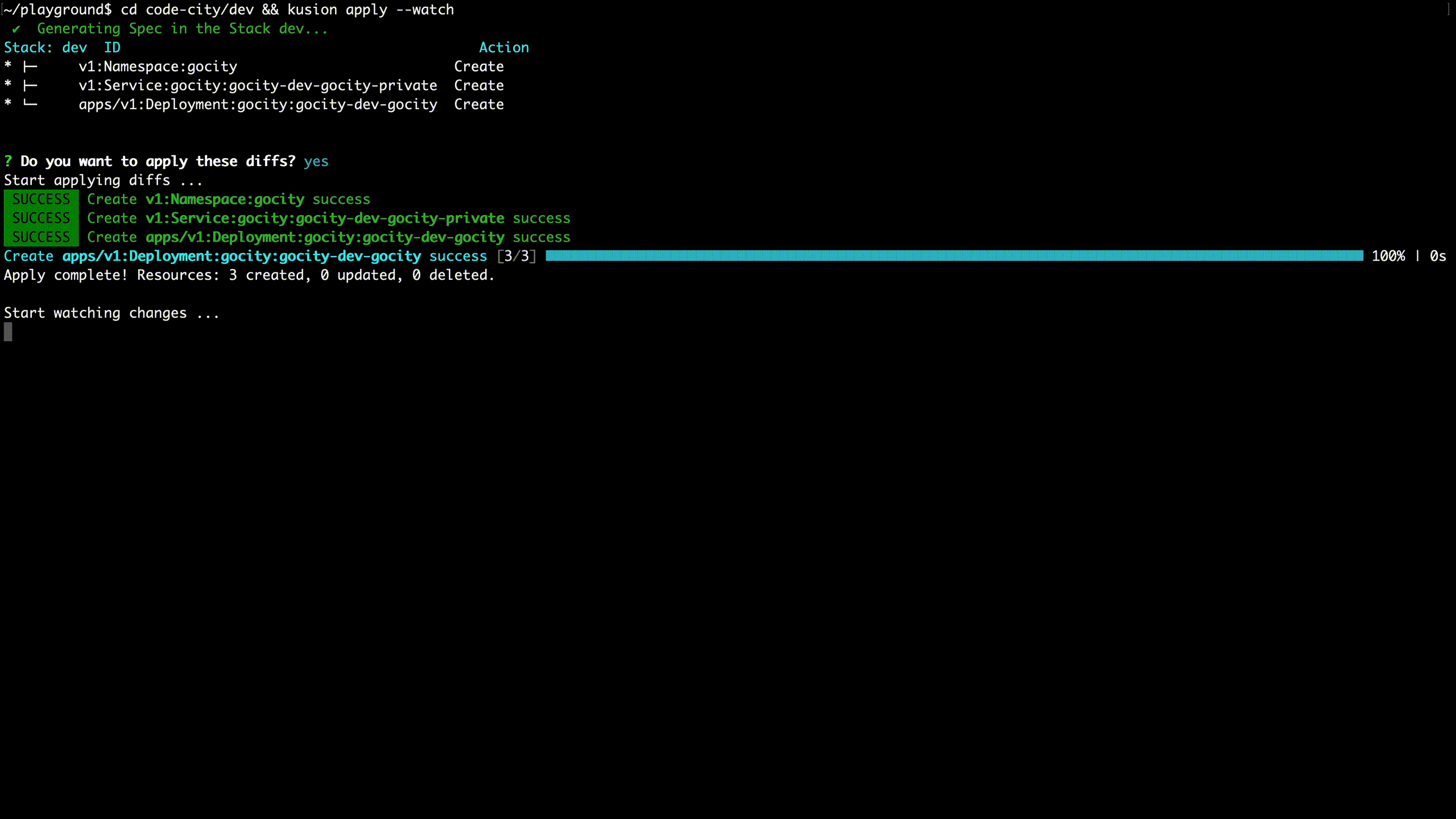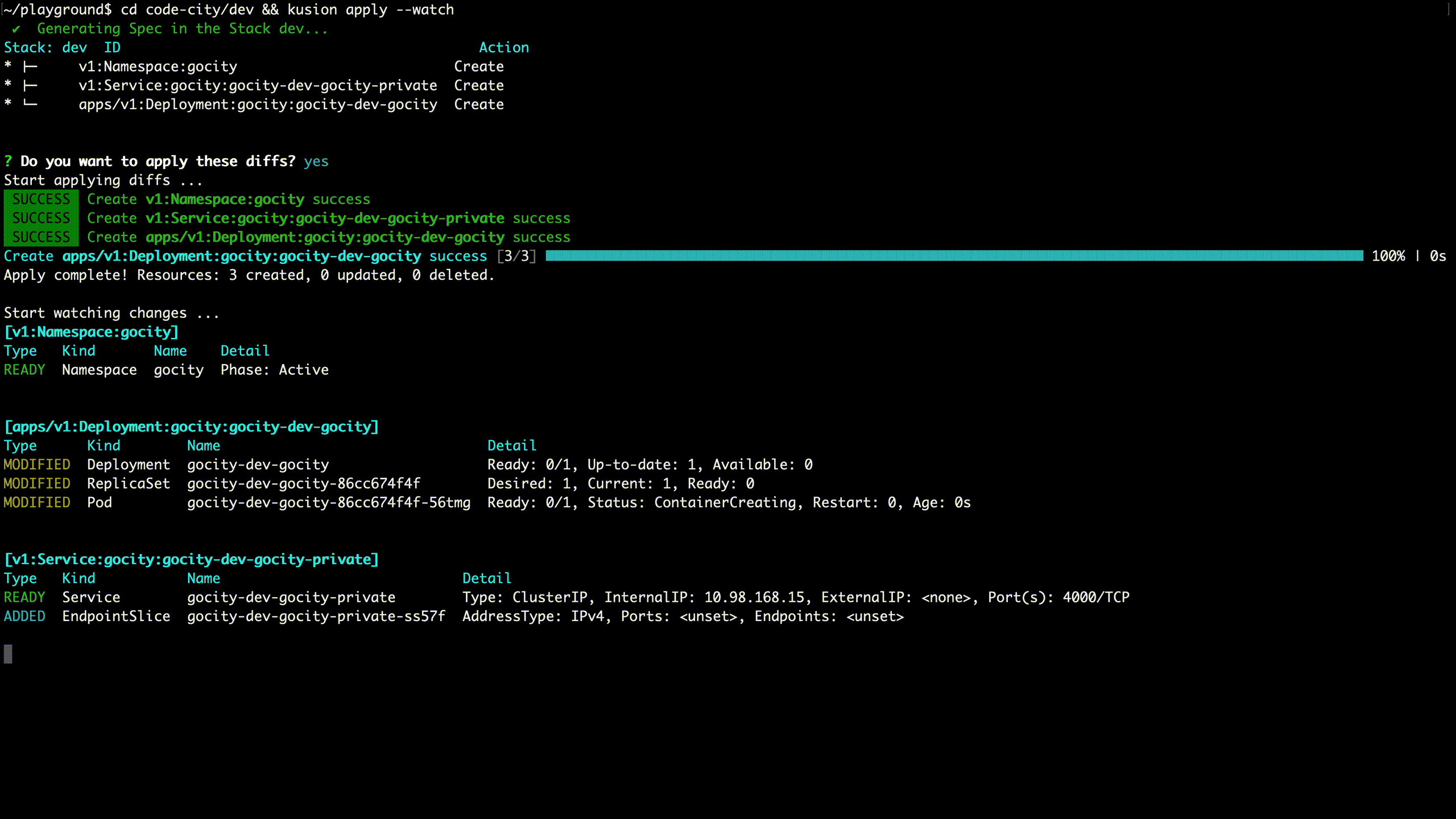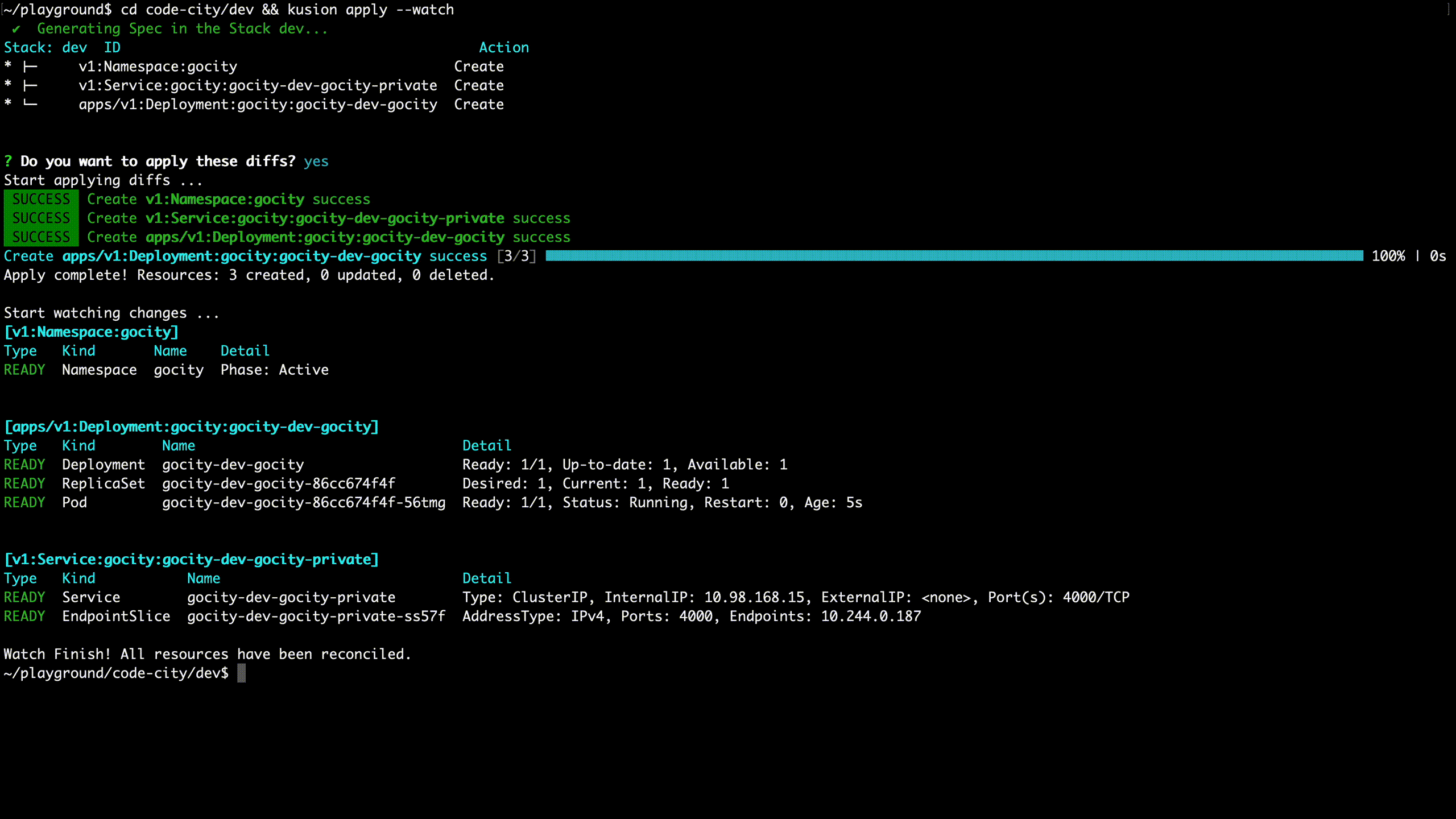
The whole system has the following characteristics
After nearly two years of exploration, this system has been widely used in AntGroup multi-cloud application delivery, computing and data infrastructure delivery, database operation, and other business fields. Currently, 400+ developers have directly participated in Konfig monorepo contribution; a total of nearly 800K Commits, most of which are machine automation code modifications; an average of 1K pipeline task execution, and about 10K KCL compilation execution per day. After Konfig monorepo compilation, 3M+ lines of YAML text can be generated.
However, all this has just begun, and the post cloud-native era has just arrived. Our purpose of open-sourcing this system is also to invite all parties in the industry to build a solution that can truly solve the current large-scale operation of enterprises. The AntGroup's PaaS team still has a lot of technology precipitation that has been verified in internal scenarios, and they will be open sourced in the future. We are far from enough, and we sincerely invite everyone to play together.
Github: Welcome to give a Star⭐️
Website:https://kusionstack.io
PPT:KusionStack: Application Scale Operation Solution in the "Post CloudNative" Era